バイオ事業
リファレンスデータの作成
Reference data construction
これまで、Genome sequencing-assembleにより得られるゲノム配列は、haploid consensusの1セットでした。
最近は、long readであること、そのread品質が向上したこと、phasingやscaffoldingに寄与する実験技術が向上したこと、assemblerの機能が向上したこと等により、assembleのみで染色体に迫るContig配列が得られようになりました。さらに、倍数体の場合、アレルごとのContigが出力されるようになっています。
加えて、シーケンシングの価格が下がったこともあり、多くの生物種についてゲノム配列の決定が試みられ、ゲノム配列の作成と遺伝子予測についてその手法が日々向上しています。
そのような状況の中で、弊社は、最新の技術を利用して、ゲノム配列のassemblyや遺伝子予測を含めたリファレンスデータの作成を行っています。
ヒトのTelomere-to-telomereにAssembleだけでトライしてみました
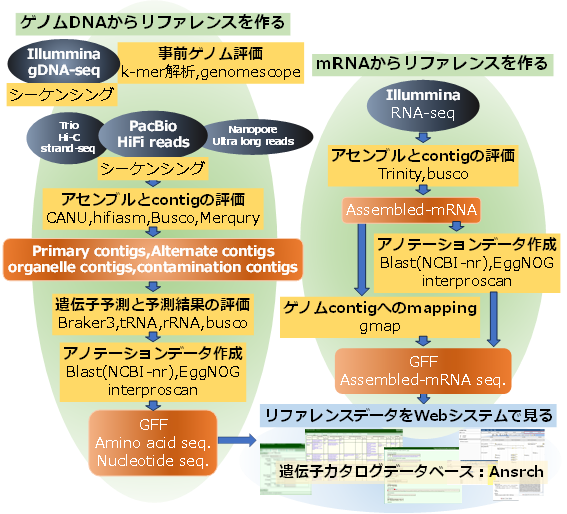
シーケンシング
複数の実験手法で得られたread配列を使用することで、高品質なゲノム配列を得ることができます。
・K-mer解析により、ゲノムサイズの予測や異質性の評価を行う。
・PacBio HiFiモードでシーケンシングを行う。
・NanoporeによりUltra long readsを取得する。※1
・Hi-Cのreadsを取得する。※1
・trio(parental illumina reads)サンプルのシーケンシングを行う。※1
・strand-seqのシーケンシングを行う。※1
※1:必須ではない。ゲノムサイズや倍数性、ご予算により検討する。
アセンブルとcontigの評価
・HiFiリード専用アセンブラでアセンブルする。
・PrimaryとAlternateのcontigが得られる。
Primary:ハプロイドコンセンサスContig
Alternate:コンセンサスContigと類似しているため採用されなかったContig
・Contig配列をBUSCO、Merquryで評価する。
・コンタミ生物ゲノムのcontigを検査し、除外する。
・オルガネラゲノムのcontigを検査し、除外する。
遺伝子予測と予測結果の評価
遺伝子予測のヒントデータとしてRNA-seqを実施していただきます。
なお、遺伝子予測は、Primary contigとAlternate contigに対して別々に実施します。
・CDS予測を行う。予測アミノ酸配列とコーディング核酸配列を得る。
・rRNA予測を行う。tRNA核酸配列を得る。
・tRNA予測を行う。rRNA核酸配列を得る。
・Primaryの予測アミノ酸配列にないAlternateの予測アミノ酸をリスト化する
・アミノ酸配列をBUSCOで評価する。
・オルガネラゲノムのcontigに対して遺伝子予測を行う。
アノテーションデータ作成
予測アミノ酸配列に対して、3種類の処理を行ってアノテーションデータを作成します。
・NCBI-nrにblastpを実施し、namedヒットリストを作成する。
・EggNOG検索を実施し、オーソログデータ(KEGG, GO, PFAM等)のアノテーションデータを作成する。
・InterProScanを実施して、ドメインアノテーションを作成する。
リファレンスデータを作成
これまでに作成したデータをまとめて、リファレンスデータファイルを作成します。
・ゲノムcontigをPrimary/Alternate/fullの3種類のファイルを作成する。
・GFF・配列のIDの整理、GFFのフォーマットの統一を行う。
・GFFをPrimary/Alternate/fullの3種類のファイルを作成する。
・Primary/Alternate/fullのGFFファイルに、アノテーションデータを挿入する。
・Primary/Alternate/fullのアミノ酸配列ファイルを作成する。
・Primary/Alternate/fullの核酸配列ファイルを作成する。
Assembled-mRNA作成とアノテーションデータ作成
ゲノムcontigから予測された遺伝子情報には、予測漏れや予測間違いがあります。よって、遺伝子予測のヒントデータを得るために行ったRNA-seqのリード配列を使って、Assembled-mRNAデータを取得し、種々のアノテーションデータを作成します。
・ゲノムcontigにmappingして、遺伝子モデル=GFFファイルを作成する。
・Assembled-mRNAにアノテーションを付与(NCBI-nrへのblast、eggnog)し、GFFに挿入する。
遺伝子カタログデータベース「Ansrch」での参照
作成したリファレンスデータをWebシステムで参照できるようにします。
このシステムにより、アノテーションデータを有効に利用することができます。